最近有个爬虫的需求,需要从网站上自动登录、爬取各种文件,所以就需要自己编写个爬虫程序进行爬取。
爬虫之前首先需要对目标网站进行分析,下面就介绍一下本次项目的一些经验。
1.抓包工具
本次抓包工具使用的是Fiddler,配合浏览器FireFox使用。
原因是Fiddler没有网页标签页的跳转问题,不容易错过网络包,而且FireFox的F12功能可视化做的比chrome好。
1.1安装
在Linux系统中安装fiddler比较方便,基本的命令行就能解决:
1
2
3
4
wget http://ericlawrence.com/dl/MonoFiddler-v4484.zip
unzip MonoFiddler-v4484.zip
sudo apt-get install mono-complete
mono Fiddler.exe
即可以打开程序主界面
1.2 https配置
这里需要配置两个地方,一个是支持https,一个是配置代理用于手机APP抓包。
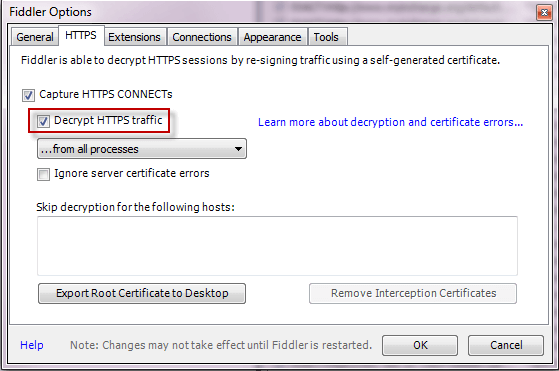
支持https配置,在Fiddler中:
-
点击Tools > Fiddler Options > HTTPS.
- 点击 Decrypt HTTPS Traffic box.
- 点击 export root certificate to desktop.完成本部操作可以在桌面看到导出的证书。
配置好Fiddler对https的支持之后,还需要在firefox中import证书。
路径为:FireFox输入about:preferences#privacy,在页面底部选择View Certificates…,然后在打开的页面中引入即可。
1.3 代理的配置
配置代理的方式也依葫芦画瓢即可:在Fiddler中点击Tools > Fiddler Options > Connections > Allow remote computer connects。
然后记得点击copy browser proxy configuration url.
回到firefox中,地址栏输入about:preferences#general,拉到页面底部选择setting,跳出的页面中选择’'’Automatic proxy configuration URL’’’ 选项,将上一部拷贝的proxy url输入,点击ok完成操作即可。
这一步的操作相当于对网络连接中引入Fiddler,效果图如下:

2.操作
完成上一部的安装和配置就可以开始抓包了。在firefox中进行网页登录之类的操作,Fiddler中讲能够完成看到所有的网络包。如下图所示:

图片中,左侧是网络包,右侧是网络包的详情。网络包详情如下所示:

3.一些trick
-
在实际抓包中,Fiddler还是得配合firefox使用,比如我一般用Fiddler去观察网络包的顺序,理解目标网站的请求顺序。然后用firefox去分析关键的请求。
-
firefox的可视化做的比Fiddler好,所以用firefox去分析具体的请求更方便。比如分析requestheaders,分析cookie
-
在最开始抓包的时候记得清空firefox的缓存和cookies,路径:F12 > storage > cookies.
-
在firefox network选项卡中右键header bar选择显示set-cookie选项卡能够帮助了解cookie是在哪里设置的。